잉이 게시물로는 OpenCV와 OCR을 사용하여 화상에서 텍스트를 추출하는 방법을 보여합니다.이 프로세스는 “텍스트 인식”또는”텍스트 검출”이라고 불립니다.제목에서 보듯 간단한 파이썬프로그램을 작성하여 텍스트를 추출합니다.추출 후, 프로그램은 결과를 텍스트로 변환합니다.이에 따른 결과를 기록할 수 있습니다.Tesseract와 EasyOCR의 2가지 방법을 봅시다.OpenCV OpenCV(오픈 소스 컴퓨터 비전)은 주로 실시간 컴퓨터 비전을 목표로 프로그래밍 기능의 라이브러리입니다.Python의 OpenCV는 화상을 처리하고 화면 크기 조정, 화소 조작, 객체 검출 등의 각종 기능을 적용하는데 도움이 됩니다.이 문서에서는 윤곽선을 사용하고 화상에서 텍스트를 검출하여 텍스트파일에 저장하는 방법에 대해서 설명합니다.OCROCR은 과거에 광학 문자 인식으로 알려졌지만, 이것은 오늘날의 디지털 세계에서 혁명적이다.OCR는 디지털 세계에 존재하는 이미지/문서가 처리되어 텍스트로 편집 가능한 일반 텍스트로 처리되는 전체 프로세스입니다.방법-1(쇼하치 세포체 사용)큐빅 OCR Tesseract는 OCR(오픈 소스 텍스트 인식)엔진입니다.직접 사용하거나 API을 사용하여 화상에서 인쇄된 텍스트를 추출할 수 있습니다.기존의 레이아웃 분석과 함께 큰 문서에서 텍스트를 인식하거나 외부 텍스트 검출기와 함께 사용하고 단일 텍스트 행 이미지의 텍스트를 인식할 수 있다.큐브의 설치 과정에서 pip을 사용하여 tesseract용 파이썬 래퍼를 인스톨 할 수 있습니다.설치 후 tesseract는 “경로”환경 변수를 편집하고 tesseract를 추가하는 것을 잊지 마세요.Tesseract및 Open을 포함한 OCR이력서 상의 프로그램은 이미지의 결과를 제시하며 사전 처리 없이 tesseract을 사용했기 때문에 정확도가 매우 낮습니다.우리는 전 처리를 하고 입방체를 적용해야 한다.사전 처리 및 검출 Tesseract출력 밀도가 떨어질 수 있는 모든 방법을 방지하려면, 화상이 적절히 사전 처리되고 있는 것을 확인할 필요가 있습니다.여기에는 다시 스케일링, 이진, 노이즈 제거 등이 포함됩니다.결과 행복은 변변치않는 것을 즐기고 사는 동안 생전에

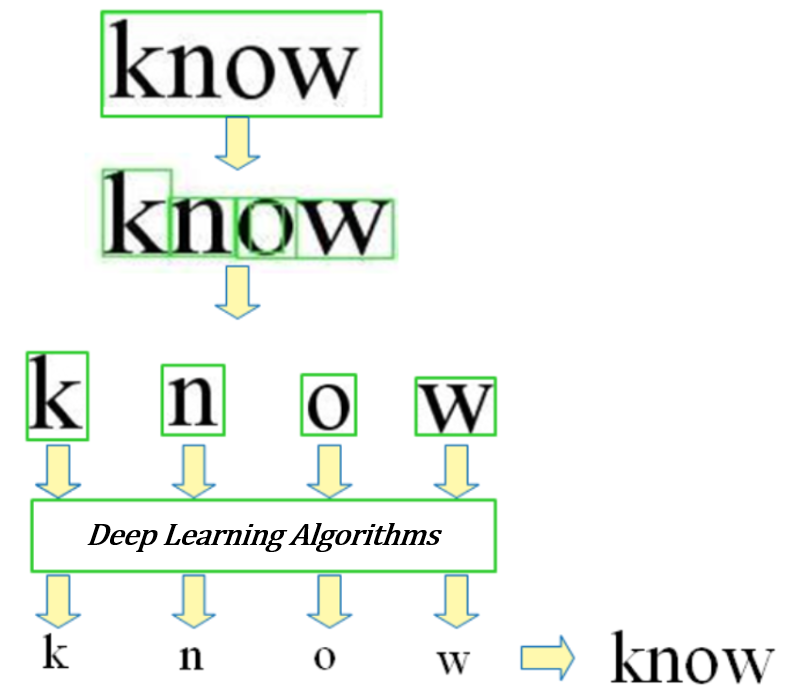
방법-2(EasyOCR사용)이지 OCR EasyOCR은 파이썬과 파이 토치 딥 러닝 라이브러리와 함께 구축되어 GPU가 있으면 전체 탐지 과정 속도가 빨라질 수 있다.탐지 부분은 CRAFT알고리즘을 사용하고 있으며 인식 모델은 CNN이다.형상 추출(현재의 Resnet사용)시아 켄 슬레이브 링(LSTM)디코딩(CTC)의 3개의 주요 컴퍼넌트로 구성된다.EasyOCR은 많은 소프트웨어 의존성이 없고 API와 함께 직접 사용할 수 있습니다.간단한 설치 OCR EasyOCR은 Pytorch라이브러리인 것으로 설치하기 전에 EasyOCROCR은 Pytorch를 설치하고 쉽게 설치할 필요가 있습니다.다음 cmd를 사용하는 OCR입니다.사전 처리와 탐지 결과 행복은 인생의 작은 것을 즐기는 것이다.결론 t본질적이고 쉬운 OCR은 예쁜 문서를 스캔하는 데에 완벽하고 정확도가 높습니다.예쁜 흰 바탕에 책, pdf및 인쇄된 텍스트를 스캔하는 작업이면 모두 편리한 툴입니다.특히 Tesseract는 스캔한 인쇄 문서에 잘 작동합니다만, EasyOCR은 일반적인 장면/임의 사진에서 텍스트를 추출하는 데 잘 작동합니다.

인기글


")